Why We Re-Architected Jama Connect® to be AI-Native
 |
|
|
|
As of today, we have completed the re-architecture of Jama Connect to AI-Native. This journey began two years ago, when we made the hard decision to re-architect to fully enable regulated, multidisciplinary engineering organizations to transition to AI-Driven Development. At the time, it was an aggressive decision given the level of investment, the uncertainty in the trajectory of LLM capability, its impact on product velocity and the adoption rates for regulated, multidisciplinary products. Now, it has become clear that AI-Driven Development can deliver step change improvements in product velocity across industries.
AI-Driven Development requires reconfiguring the product development process and retooling to fully leverage AI engineering agent speed into product velocity gains. The product context layer (requirements, decompositions, relationships, test cases, test/simulation results, comments, reviews, etc.) that Jama Connect provides across all engineering disciplines and across all product versions, variants, branches, baselines and releases is even more critical in AI-Driven Development since AI agents can only leverage explicit knowledge (not tacit knowledge in engineers’ heads) and automated, parallel activity is required to achieve the desired product velocity gains.
An AI-native architecture at the product context layer must solve the following challenges for engineering organizations to achieve the desired product velocity gains from AI-Driven Development:
Addressing these challenges requires an architecture that at its core can manage and relate semantic data across all elements in the product graph and maintain a live state while they transform, branch/merge and trigger events. While competitors offer simple object relationships (object A has a link to object B), we provide semantic relationships that carry intent, direction, and logic. These semantic relationships are necessary for LLMs to make accurate, consistent and efficient inferences from product context information.
In competitive comparisons, our product graph delivers significantly greater LLM inference accuracy, consistency and token efficiency. This is critical as software development teams are already exceeding token utilization budgets and looking for efficiency gains.
The graphic below shows the five layers of our AI-native architecture leveraging the most interoperable, proven and scalable approaches:
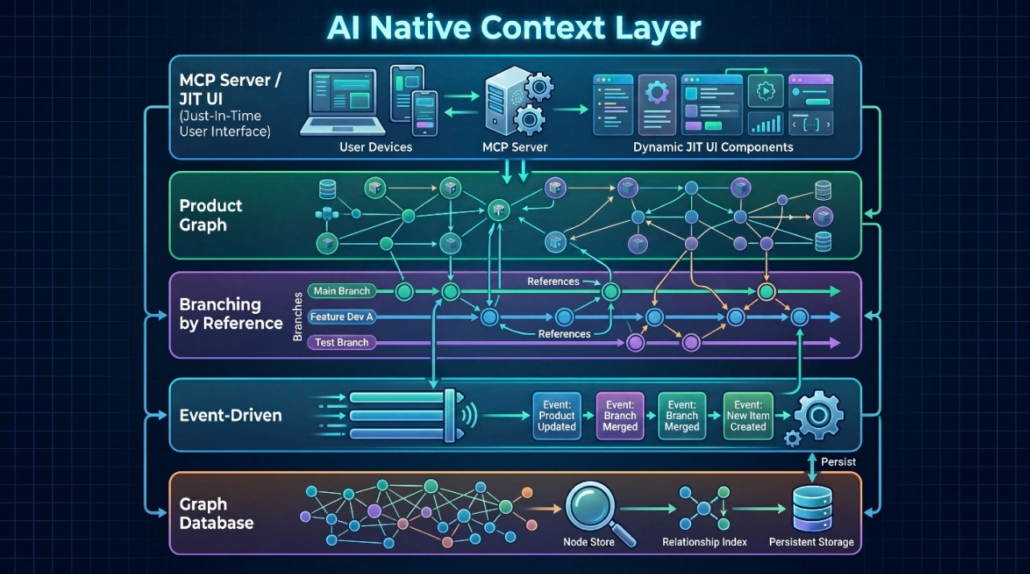
AI-Driven Development fundamentally changes core assumptions of how engineering happens and requires an AI-native product context layer. Legacy architectures were built decades ago and assumed that the product context layer was tacit knowledge in engineers’ heads and not something that needed to be semantically modeled in the system. But LLMs require all relevant tacit knowledge to be explicit and infused with meaning in a semantic product graph.
Legacy tools focused on making the manual tasks of individual engineers more efficient through the UI of a discipline-specific desktop tool with information saved in flat data structures that do not support semantic relationships. Legacy architectures cannot support AI-Driven Development because they lack the 5 key AI-native architecture elements.
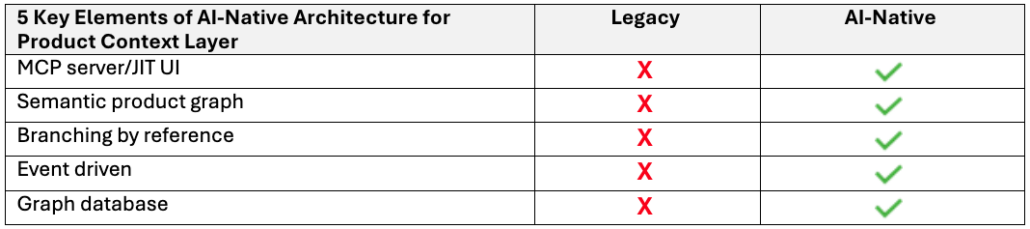
Achieving the 10X product velocity gains from AI-Driven Development requires an AI-native architecture at the product context layer. We invite you to engage with us and start working with the Jama Connect MCP™ released today.