The popularity of Agile methodology, along with the increasing trend toward automation in software development, has pushed requirements management solutions to evolve. The misconception that Agile methodology doesn’t work in regulated industries is outdated, but regulated industries have, justifiably enough, specific expectations of their requirements management (RM) solutions, and those expectations continue to drive change in the market.
A recent report from Forrester Research, “Now Tech: Agile Requirements Management Tools, Q2 2018,” outlines the state of the market for Agile RM solutions and lays out the questions customers should ask when selecting the right requirements solution for their space.
Why invest in requirements management?
According to Forrester, it’s not just highly regulated industries and organizations involved in complex product development that can benefit from a requirements solution.
In spite of the “a coalition of Agile aficionados arguing that it’s unnecessary to formally collect and manage requirements,” the report suggests that best-in-class RM solutions can significantly improve product design and delivery for Agile development teams: “In the face of increasing regulations, connected products for the internet of things (IoT), and scaling Agile practices, AD&D [application development and delivery] leaders long for something to bring traceability and auditability to their processes without sacrificing speed.”
Why do you need traceability?
The right RM solution enhances development transparency through traceability. Traceability is a roadmap that shows you where in the product development lifecycle each requirement or business rule was implemented. With traceability, teams are better-equipped to perform impact analysis – i.e., to assess the consequences of proposed changes. This is crucial in complex product development, where simple changes can have far-reaching impacts, and it’s tough to isolate every system component that might be affected by a change in requirements.
Teams facing increasing complexity, pressure to comply with industry regulations, and the need to measure customer value must be able to search, track, and connect interdependent requirements. Achieving a faster time to market demands that teams collaborate quickly and effectively while they work on building out traceable requirements and test cases.
Why is it important to reduce tech debt?
Forrester reports that RM solutions can also help Agile teams reduce technical debt. Agile teams are focused on moving quickly, so they sometimes fall back on fixes that are easy to implement right now, but that will require rework down the line. Basically, tech debt refers to the work you’ll have to do tomorrow because you cut corners today.
You can’t avoid tech debt entirely, and you shouldn’t even try; you can’t move quickly without accumulating a little. But as the Agile methodology becomes even more widespread and project complexity continues to grow, RM tools will help development teams understand what has been done, what will be affected in the next sprint, and how to improve collaboration within distributed teams.
Finally, the report suggests, development teams can use RM solutions to embed visual modeling, design, and prototyping into their product development process. By modeling customer journeys, business processes, system designs, and user-interface components, teams can ensure that the final deliverable meets stakeholder expectations.
How has Agile changed requirements management?
Agile teams expect to move fast, so RM solutions looking to penetrate this market must meet developers’ need for speed. Transparency is another priority for Agile teams, and the transparency and traceability offered by an RM platform empowers teams to move beyond what the report dubs “static, text-based requirements.” As we noted above, traceability enables more effective and timely impact analysis, a critical consideration for rapidly evolving requirements.
Even though plenty of Agile teams see the value of a requirements solution, Forrester notes that “vendors have shied away from the term [requirements management] and evolved their offerings to fit new product niches.” Part of this avoidance of the term is because people tend to associate “requirements management” with clunky, tedious processes that lacked the efficiency and ease of use that current solutions offer. In contrast, the requirements solutions favored by Agile teams are less highly specialized; they have different capabilities and focus on different segments of the development lifecycle. As such, the Forrester report suggests that Agile teams consider whether the best solution for them is not one solution but a combination.
How do you choose the right requirements solution?
To maximize success in requirements management, the report found, teams should choose a platform that works for their discipline (product management, engineering) and their industry (medical, automotive).
As we wrote in our recent post, “Systems Thinking for Complex Product Development,” collaboration is easier and delivers better results when teams are encouraged to find approaches that are effective for them within their disciplines.
Before investing in a RM solution, Forrester suggests that Agile leaders engage in some strategic thinking to determine which RM platform will deliver the most value in concert with other tools and solutions. Decision-makers should:
Audit the tools already in use. Company and industry requirements drive investment, so understanding the existing ecosystem of tools already in place at your organization is essential in choosing the best RM solution for your particular needs. Take a close look at your Agile planning/project management, design, testing, and continuous integration tools to determine the best solution for your organization.
Identify where requirements fall apart. If you have issues uncovering requirements to begin with, consider a tool with more advanced collaboration, design, and modeling capabilities to help you define exactly what you want to build. If your challenge is understanding the impact of requirements, passing tests, or avoiding bugs in production, you need a tool with greater traceability and robust reporting capabilities that can integrate with automated testing tools.
Anticipate change. What changes are ahead for your industry? How will you be affected by new or evolving government regulations? Will your products be integrated with sensitive customer information? Now is the time to start laying the foundations for compliance with these future requirements.
Right-size the need for documentation. What’s the future of Agile at your organization? Are you looking to scale Agile companywide? Even if you don’t need a super-robust RM solution now, you’ll need to implement some governance early unless you want to be drowning in technical debt.
Systems thinking is an approach to solving complex problems by breaking their complexity down into manageable units. This makes it easier to evaluate the system holistically as well as in terms of its individual components.
A high-level, interconnected view of the product development process can yield new insights into how products are defined, built, released and maintained. Product managers sit at the center of the product development system, so they’re primarily responsible for understanding and directing the system.
You can think of systems thinking as a diagnostic tool: a disciplined approach to examining problems more completely and accurately before taking action. Systems thinking encourages teams to ask the right questions before charging ahead under the assumption that they already know the answers.
For product teams grappling with exceptionally complex design specs and requirements, systems thinking opens the door to procedure-level improvements and the ability to take full advantage of solutions that support them.
In this post, following up on our recent piece about systems thinking for medical device development, we talk about how product managers can leverage systems thinking to improve their processes.
The Iceberg Model: How to Put Systems Thinking Into Action
The Iceberg Model is a practical way to put systems thinking into action. We borrowed the following excellent example from the smart folks at the Northwest Earth Institute.
Picture an iceberg (doomed ship optional). The tip sticking out of the water represents the event level. Problems detected at the event level are often simple fixes: You wake up in the morning with a cold, so you take a couple of ibuprofen to feel better. However, the Iceberg Model encourages us not to assume that every issue at the event level can be quickly resolved by treating the symptom.
Just below the event level is the pattern level. As the name suggests, this is where you detect patterns: You catch more colds when you skimp on sleep. Observing patterns helps product managers forecast events and identify roadblocks before they rear their ugly heads.
Below the pattern level is the structure level. If you ask, “What’s causing this pattern?” the answer is likely to be structural. You catch more colds when you skimp on sleep, and you skimp on sleep when you’re under pressure at work or when your personal life is causing you stress.
The mental model level is where you find the attitudes, beliefs, expectations and values that allow structures to function as they do. These attitudes are often learned subconsciously: from our parents, our peers, our society. If “I’ll sleep when I’m dead” is part of your mental model, you’ll have trouble making the attitude and behavior adjustments that could help you avoid another cold.
The Iceberg Model encourages you to stop putting out fires and start addressing deeper issues. Using this model can align your team members through shared thinking and reveal opportunities to make small changes to the process that will yield big benefits.
More Visibility, Superior Collaboration
With a systems-thinking approach, complex product development teams can improve their processes by enhancing visibility and enabling more seamless collaboration and coordination between stakeholders.
Complex product development requires that the right people have visibility into the right parts of the system at the right time. Systems thinking drives teams to coordinate and communicate through a common system need. Collaboration becomes easier and more productive when teams are free to find approaches within their disciplines that are most effective for them, while still meeting the needs of the system.
Compliance & Traceability
Simple changes to requirements can have far-reaching impacts, and it’s hard to isolate every system component that could be affected by a requirement modification. It’s easier to assess the impact of proposed changes – that is, to perform valuable impact analysis – when you have a roadmap that shows you precisely where each requirement or business rule was implemented in the software. Traceability gives you that roadmap.
By helping identify all the areas you may have to modify to implement a proposed change to a requirement, traceability enables impact analysis. With proper traceability, you can follow the life of a requirement both forward and backward, from origin through to implementation.
Traceability is difficult to establish after the fact, so teams can use a tool like Jama Connect from the beginning to track tasks, keep tabs on evolving requirements and contextualize test results. Traceability gives teams confidence in the safety and quality of their products, and helps them demonstrate compliance with national and international standards for highly regulated industries.
Since lower-level requirements and outputs are defined within the context of a specific system need, traceability allows teams to understand that context and the downstream impacts of any change made.
Customized Solutions for Complex Product Development
Organizations across a huge range of industries are engaged in complex product development. Systems thinking encourages teams to work through a common system need, while still employing the approaches that work best within their disciplines. To assist, Jama Connect provides visibility throughout the product development cycle and keeps stakeholders connected to minimize miscommunication and unnecessary rework.
And our Jama Professional Services consultants work with you to understand your objectives and configure the platform to support your process in the optimal way. As your process, people and data change, our experts help you realign development methodologies to best practices, elevate your requirements management skills and reinforce your process. For larger teams that want ongoing deployment and optimization assistance, our adoption services give you a team of experts at your fingertips.
Learn more about some of the ways systems thinking helps overcome complex product development with our whitepaper, “Systems Engineering and Development.”
The Jama Support Community is a forum for Jama Software users to interact and collaborate with other users and with Jama support engineers. It’s full of resources for everyone from novices to masters, including tutorials and webinars, help guides and FAQs, feature requests and announcements and a robust knowledge base. For today’s post, we spoke with one of our Jama Support Community power users — frequent contributors with great questions and powerful insights into using Jama — about how their organization uses Jama and the value they’ve seen from the Support Community.
Srilatha Kolla works on the DevOps team at at Hill-Rom Cary in the Raleigh, North Carolina area. Hill-Rom’s Clinical Workflow Solutions team develops medical devices that protect patients by anticipating the care they will need and communicating that information to their healthcare providers.
The process of developing these Class II and Class III medical devices is heavily regulated by the FDA, and Kolla’s team needed to achieve full traceability in order to satisfy these requirements. Hill-Rom was using IBM Rational DOORS for their requirements and test case management prior to 2012, but it didn’t meet their traceability needs, among other shortcomings.
Kolla, who started her career as a developer at IBM, was on the Quality Engineering team at Hill-Rom when they began looking for a superior solution. Her QE team evaluated several options before choosing Jama Connect™ in 2012.
Since then, Kolla has moved to the DevOps team, where she’s responsible for deploying and managing processes to help development, requirements and quality engineering teams build, test and release products that are safer and more reliable. Her team is closely involved from the requirements stage to coding, testing and verification of the product, and she’s responsible for managing the solutions, including Jama Connect, that her team depends on.
Kolla’s DevOps team serves as the Jama administrator at Hill-Rom, but the development, requirements and quality engineering teams, she says, also “live in Jama Connect day in and day out.” Among the organization-specific best practices her team has developed is a multi-project structure, which works better for them than a single, more complex project structure.
As an FDA-regulated company, Kolla says, Hill-Rom values Jama Connect for its traceable requirements and test case management: “That’s what we depend on highly.” She’s also a fan of the Review Center in Jama Connect. The Review Center enables teams to collaborate without hunkering down in the same room or emailing a Word document back and forth. Stakeholders can also review and sign off on requirements within the Review Center, which comes in handy when you need to reach consensus between team members quickly.
Kolla began using the Jama Support Community to get her questions answered. She wanted to see how other people were using Jama to address the same product development challenges her team was facing. As Kolla says, “We’re definitely not the only ones using this platform.”
Like many Jama customers, Kolla’s team uses Jama Connect in conjunction with Jira, so she turns to the Support Community to ask relevant questions about Jama’s functionality and interconnectivity with Jira, Microsoft Office and other tool suites. Given her team’s focus on traceability, Kolla has often sought Jama-related input from other users on things like item management, defects, Test Center, Trace View, Coverage Explorer, Reuse and Filters.
Stay tuned for more posts on how Jama users are leveraging the Jama Support Community to get the most out of the platform. In the meantime, connect with Sri and other fellow Jama users on the Jama Support Community.
Systems are only becoming more complex. When mapping out system requirements, relationships diagrams can quickly start looking messy and confusing.
And the deeper down you go in the relationship tree, the more items branch from the trunk and the interconnections become countless. However, the information contained within these diagrams is critical. An accidental alteration to a relationship could lead to catastrophic failure.
This is one area where Jama Connect’s Trace View is providing an increasing amount of value for our customers. Trace View allows product development teams to maintain Live Traceability, view how items link together and trace them as they change at any point in time.
Instead of retracing your steps to find gaps in coverage or wasting time managing multiple documents to update requirements, you can always keep your teams moving forward with Trace View. It is easy to manage upstream and downstream relationship impacts, see missing relationships and analyze item relationships.
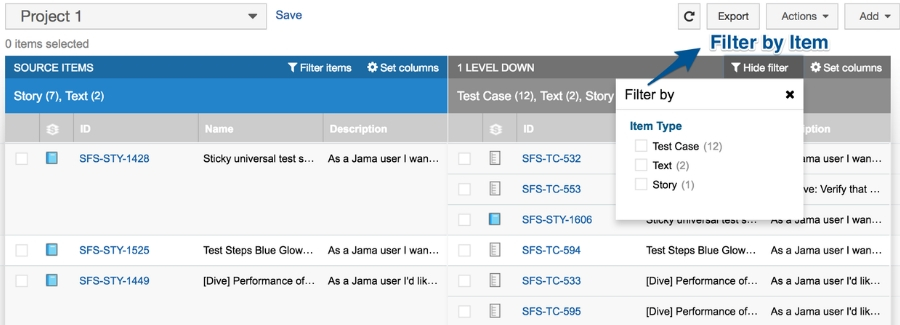
And now, we’ve made Trace View even better. The latest enhancement to Trace View — Trace View Filtering — allows product development teams to quickly filter through items and analyze data that is pertinent to their search criteria.
To understand why Trace View Filtering is so important, let’s take a typical scenario where you only want to see item test cases and not be distracted by text, stories or defects.
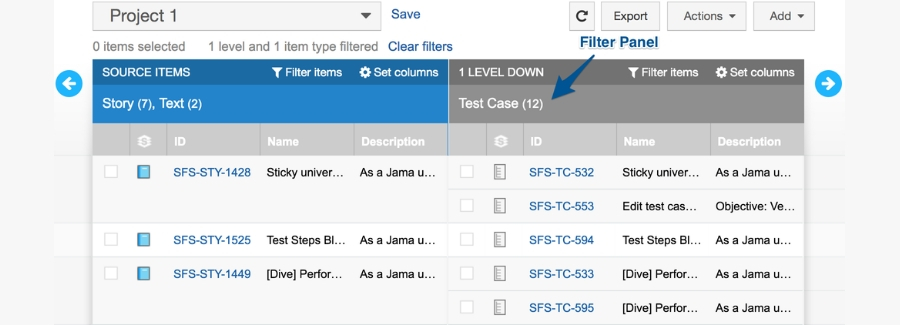
Filtering allows users to quickly shed item types from the views that do not apply to the current situation.
Each column filters independently, because item types may appear at more than one level in Trace View. And the filter panel allows users to see all item types found in a column and filter them out.
With Trace View Filtering, you can also save and share your filters across teams.
An effective traceability system is important to the success of any product development. With Trace View, you can increase visibility, save time and eliminate risk throughout your product development lifecycle.
To learn more about how Trace View Filtering can help you find item types quickly in Trace View, email your Jama Connect account manager or contact us directly.
Once your team uses traceability for medical device development, you’ll wonder how you managed any other way.
Building traceability into the process is a critical step to ensure regulatory needs are met, requirements hit and changes managed along the way.
When brought to market, the margin of error for medical devices is near zero. Any defects not discovered and corrected during development can result in patient injury or death, not to mention devastating legal consequences for the company that released the product. With the stakes so high, every step of the development process must be traceable.
Traceability ensures a collaborative and unified timeline from conception to market, meticulously documenting everything in between. It also allows stakeholders to continually monitor timelines, and view how changes affect the team and the necessary response needed.
In essence, traceability lets teams map out interdependencies at each phase of development, ensure all compliance regulations are continually met and changes conform accordingly.
A Unified System of Record for Medical Devices
Heavily regulated products like medical devices require comprehensive audit trails of changes during development.
Traceability enables teams to view and analyze all changes made during development — including who made the change, what it was, when it was made and why it occurred in the first place. Since a traceable development project is kept in a unified system of record, it allows you to revert back to an earlier version of the changes.
Traceability also saves time and effort by communicating requirement modifications directly to the relevant group or individuals responsible in real-time, instead of forcing various team members to pore over the spec to determine if the latest change affects them.
Streamlining Communication for Medical Devices
Collaboration has become a central component of product development teams, and it’s the core of modern traceability.
Bringing all stakeholders together ensures compliance as well as productivity. With everyone on the same page, any potential questions an auditor could raise about process or a development decision can be easily answered. Traceability also makes a product lifecycle and its surrounding processes a living, ongoing entity as opposed to an afterthought. This is vital with the increasing complexity of today’s market.
Bringing Globally Distributed Teams Together
Multidiscipline teams working with different processes and systems must be able to see and understand what their fellow collaborators are doing.
This is especially true in complex spaces like medical device development, and traceability lets remote teams move faster and work together in a more cohesive way. This empowers them to independently make important decisions, based on correct and current data.
Anyone pulled into the conversation during development can be quickly brought up to speed without impeding on the momentum teams have already built.
Adopting Traceability for Medical Devices
Today’s medical devices are so much more than metal and plastic. Software plays a big part in communicating data to patients and doctors. This means the software component must be as traceable as the hardware, since a single instance of incorrect code can become a major liability.
All risk must be considered throughout the product design and implementation. Proper traceability establishes consistent, accurate links between each step of work to ensure the framework protects the user and organization.
Traceability isn’t just about information tracking, it’s about being able to call up that data in the correct format to share with customers and auditors. With Jama, you can track your design and verification within the solution.
Some of our customers complete their risk management analysis around why specific severity was assigned or why a mitigation was applied in a certain way. A single spot for modern traceability around the product you’re developing makes it simple to find the information you need about why decisions were made, as well as understanding their upstream and downstream impacts.
Learn how Jama uses live traceability to let medical device developers locate the source of any decision, manage risk and reference similar past projects in our webinar, “Live Traceability: The Golden Key to Proof of Compliance.”
Amongst the powerful processors waving about onstage and videos projected on the walls of driverless cars navigating the streets of New Jersey, Jensen took pause in his address to put an emphasis on a word and concept not often used in the semiconductor industry: traceability.
The Tip of the Iceberg
To begin his segment on automotive functional safety, Jensen makes use of a common metaphor; saying, “Functionality is plenty challenging. The performance of these computers, the algorithms that have never been done before, the large-scale system integration with all different configurations of sensors is so complex, it is the most complex development we’ve ever done.
“And yet…”
In Jensen’s own words: “That’s just the tip of the iceberg.”
Beyond functionality, Jensen explains, “the most important feature of a self-driving car is not that it drives by itself; the most important feature is actually safety.” That is, how do you make a system respond safely, when the system itself fails?
This is clearly no easy achievement. In fact, Jensen argues it is so “extraordinarily complex” that it is literally easier to make a car drive by itself in the crowded streets of New Jersey than it is to ensure a system is functionally safe. After all, functionality is just the beginning.
From Culture, to Technology, to Tools
So, in the face of an engineering feat so “extraordinarily complex,” what do you do?
For NVIDIA, Jensen says, “it requires a holistic system approach, from culture, to technology, to tools.” This point is rather straightforward: to manage something so “extraordinarily complex” your entire organization needs be in unison, from the company culture to the tools by which your engineers use.
However, the next step in Jensen’s progression isn’t quite so black and white. With his own personal flair, Jensen announces, “We have the ability to achieve traceability for as long as we shall live.”
Hidden beneath this grandiose verbiage is a slightly ambiguous concept: traceability. Thankfully he continues, “If something were to happen, we can trace it all the way back to its source to improve and mitigate risk in the future.” Now we’re talking.
Achieving traceability means that everything throughout development — whether it be meeting minutes, email exchanges, specification tradeoffs, data sheets, management approvals, verification tests, you name it — is recorded, tracked in real-time and put to use to ensure that “if something were to happen,” or an error were to occur, you have the ability to immediately flag it, trace it to its source and fix the problem.
The question I then pose to you is, if something goes awry in your next highly complicated project, as you’re barreling a million miles an hour in the pursuit of your deadline, will your traceability help?
A product development team’s success or failure hinges on the many decisions it makes throughout a development cycle. Those choices are influenced by a myriad of factors, including balancing timing, regulations, production costs, customer feedback and benefits to the end user.
Given the complexity of products today, it takes multiple team members to weigh-in on key decisions. And the number of decision points are only growing as products get more complex, making it even tougher to adequately weigh all the options and trace their impacts.
Decisions under pressure: Making an already complex process even tougher
Those who have been through crunch time know the volatile element hanging over all decisions throughout development is pressure — whether it’s related to deadlines, complexity or the organization. Here are some examples.
Decision Pressure = Not Enough Time
Depending on the number of stakeholders, their schedules, and level of involvement in the development process, receiving input on key changes or milestones can be an extremely tedious and time-consuming endeavor.
Getting multiple parties to sign off on a plan traditionally takes time, and it becomes nearly impossible if circumstances change while working through an especially sluggish sign-off process.
Decision Pressure = Not Enough Data
When debating decisions with team members — whether they’re executives, engineers or interns — good data strengthens the argument.
Running on instincts works for certain things, but if you’re constantly making tough calls without solid data, there’s a high probability of hitting problems— such as rework, delays and failures— later on.
Having visibility into the data used to define original requirements, as well as any new information causing requirements to change, is essential.
Decision Pressure = No Visibility Into Impact
Any new decisions must also take into account how they will impact the original requirements. One tweak to a requirement may cause ripple effects that impact the product in unintended ways.
Issues may be uncovered in the testing stage, but if one tiny change means a complete redesign, you’re going to miss market opportunities and blow past your budget.
Modern Traceability Relieves Decision Pressure
The practice of traceability was created to demonstrate that good decisions were made throughout development. While it’s a concept that has been around a while, it has had to evolve to keep up with a transforming, increasingly complex and time-sensitive product development process.
Building off the gains of the past, modern traceability is a new way of handling the process that’s built to support how people think and work.
Critically, it’s focused not just on the actions of an individual person, but entire teams over time. And this provides many benefits.
Less Pressure from Connected Data = Saved Time
Having a platform to power modern traceability is crucial. At a minimum, it needs to record, share and display data.
Crucially though, it also must be easy to use — so anyone on your team, from any experience level, can take advantage of it immediately with only a small learning curve.
Using modern traceability tools allows you to quickly show how the work being done is related to the company’s overall goals, which speeds up review cycles.
Less Pressure from Connected Data = On-Demand Context
Instead of data only being available at the end of a project or during major milestones (when people have the time), modern traceability’s data is continuously updated by the entire team and it’s always live and accessible.
For example, if all requirements have direct links to the original intent of the organization for a project, it’s easy to see whether a change is in alignment or deviating from that goal.
Simply look upstream from a requirement (or test, or design, etc.) to see why that piece of work existed. This provides valuable context ahead of any decisions to make a change. Have questions about why? Ask the person who added that upstream content directly.
Less Pressure from Connected Data = Clarity on Impacts to Requirements and People
While traceability practices have always connected test data to requirements, modern traceability delivers visibility into how people are connected to, and impacted by, changes to ongoing development work.
When a test fails, not only is it possible to see what requirements are impacted, modern traceability also offers the ability for affected parties to be notified immediately. No waiting for a major milestone review when pivots are costly. It amplifies the effectiveness of collaborative work already being done, and works best when you’ve got the right tool to utilize it.
The benefits of modern traceability are increasingly becoming essential for teams serious about creating better products with less waste and timelier cycles.
With modern traceability, you can connect data to make informed decisions faster and do your job better.
Too often products fail due to poorly managed requirements. A requirement is a document that defines what you are looking to achieve or create – it identifies what a product needs to do, what it should look like, and explains its functionality and value. Without clearly defining requirements you could produce an incomplete or defective product. It’s imperative that the team be able to access, collaborate, update, and test each requirement through to completion, as requirements naturally change and evolve over time during the development process.
There are four fundamentals that every team member and stakeholder can benefit from understanding:
Planning good requirements: “What the heck are we building?”
A good requirement should be valuable and actionable; it should define a need as well as provide a pathway to a solution. Everyone on the team should understand what it means. Good requirements need to be concise and specific, and should answer the question, “what do we need?” Rather than, “how do we fulfill a need?” Good requirements ensure that all stakeholders understand their part of the plan; if parts are unclear or misinterpreted the final product could be defective or fail.
Collaboration and buy-in: “Is everyone in the loop? Do we have approval on the requirements to move forward?”
Trying to get everyone in agreement can cause decisions to be delayed, or worse, not made at all. Team collaboration can help in receiving support on decisions and in planning good requirements. Collaborative teams continuously share ideas, typically have better communication and tend to support decisions made because there is a shared sense of commitment and understanding of the goals of the project. It’s when developers, testers or other stakeholders feel “out of the loop” that communication issues arise, people get frustrated and projects get delayed.
Traceability & change management: “Wait, do the developers know that changed?”
Traceability is a way to organize, document and keep track of the life of all your requirements from initial idea through to testing. By tracing requirements, you are able to identify the ripple effect changes have, see if a requirement has been completed and whether it’s being tested properly, provide the visibility needed to anticipate issues and ensure continuous quality, and ensure your entire team stays connected both upstream and downstream. Managing change is important and prevents “scope creep”, or unplanned changes in development that occur when requirements are not clearly captured, understood and communicated. The benefit of good requirements is a clear understanding of the end product and the scope involved.
Quality assurance: “Hello, did anyone test this thing?”
Concise, specific requirements can help you detect and fix problems early, rather than later when it’s much more expensive to fix. In fact, it can cost up to 100 times more to correct a defect later in the development process after it’s been coded, than it is to correct early on while a requirement. By integrating requirements management into your quality assurance process, you can help your team increase efficiency and eliminate rework.
Requirements management can sound like a complex discipline, but when you boil it down to a simple concept – it’s really about helping teams answer the question, “Does everyone understand what we’re building and why?” When everyone is collaborating together and has full context and visibility to the discussions, decisions and changes involved with the requirements throughout the product development lifecycle, that’s when success happens consistently and you maintain continuous quality. Not to mention the process is smoother with less friction and frustration along the way for everyone involved. And, isn’t that something we’d all benefit from?
Recently I decided it was time I improved my cooking skills. Being an analytical person, I spent a considerable amount of time deciding on an approach. One must have a strategy, measurements for success, and a repeatable pattern of course! (Right?) Given that I like to run repeated experiments, I decided to take a set of dishes I wanted to master, find a few variants (similar recipes), and repeat them until I understood what specific ingredients, tools and techniques were essential.
The act of repeating recipes itself turned out to be the valuable lesson. Following the steps, not isolating the science behind it each decision, allowed skills to be internalized in concert. There is no single essential technique, or secret ingredient. Having a full toolbox of interrelated skills and past decisions to call upon is what works. While it’s hard to measure the exact causes for success, my larger goal is being met as my cooking improves!
Using modern traceability in product development, those that allow you to connect data and people across an organization, follows a similar pattern. Some complex situations call for traceability recipes, others just common sense. It’s a collection of related tools and behaviors used for a purpose – successful product delivery. It’s flexible, adaptable, and evolving to keep up with the demands of building high quality products fast. While I might have tried to limit or isolate traceability like it’s a single secret ingredient, I’m finding it’s more valuable to consider its many forms together as I did learning to cook.
Below are some of the goals our customers have found traceability can in fact solve. Recipes from master chefs, if you will.
Finding the Source of a Decision – Before you get to work making a change, use traceability to understand the why behind decisions.
Use Modern Traceability to keep conversations connected as context, and do so continuously. This reduces the time required to find the source of past decisions, and doesn’t rely on flawed human memory to answer the question “why did we decide that again?”
What’s connected: Track decisions associated to requirements changes as closely to the requirement itself as possible, such as in the comments. Use tools like Jama’s Review Center to keep comments all related to the same set of data clearly saved in one spot, and referenceable later.
Adapting to Challenges and Change – When a major change does need to happen, easily see the ripple effect up and downstream at any point in a project, not just milestones.
Use Modern Traceability to see potentially risky changes coming. When you track and relate requirements as you work, it’s much easier to see the impacted data when a change is proposed. Teams can adapt more quickly because the map of how your product is built exists throughout the project, not just at major milestones.
What’s connected: Associate people to the requirements themselves. Use this to quickly see who’s related to data, tests, requirements, etc. connected 1-2 levels in either direction. Notify connected people automatically when major things change.
Managing Risk – Keep track of risks and mitigations as you work, in a shared tool so re-use of similar data is easy and visibility is high.
Use Modern Traceability to reduce the heavy lift of managing risk data. Update your tracking of risk dynamically, tied to requirements, and visible to the entire team working on your product. Generate a view of how you’re doing along the way, and share it long before an audit.
What’s connected: Configure your teams’ traceability map to include links from requirements to risks, mitigations, environmental context, and test data.
“Are we there yet?!” Status Updates – Everyone needs to know how the team is doing, at different times and at different data granularities.
Use Modern Traceability to shared dynamic views of progress, at the level of data that makes sense for the audience. Skip generating manual static reports, and instead share live, accurate ones.
What’s connected: For this to work you need a common language, and that is derived by connecting all the levels of product data so everyone has a familiar anchor point. Create relationships from the highest level market requirements, to draft designs, to requirements, to passed test in Jama. This gives every use the ability to pick a data type they are familiar with and see progress at that level, whether that means seeing the status of the requirements a marketing goal decomposes to, or looking at all the downstream test status for a particular hardware component.
Referencing Similar Past Projects – By maintaining data and relationships throughout a project, by the end that project will be full of rich insights that can be used in the future.
Use Modern Traceability to look at past projects as a whole, across all the data types from requirements to comments. Find projects that were successful, and use that as a starting point for new projects.
What’s connected: Everything! Data should be explore-able, like a map, so anyone can self-serve when they want to know answer to questions like “what did we do last time?”
The product development world is getting more complex, time pressured, and all in a changing environment of rules and regulations. To keep up, your traceability practices need to adapt, to take into account how humans and teams actually think. As your team adopts new traceability practices, though, I humbly encourage you to approach it like learning a complex skill such as cooking. It’s not any one practice, ingredient or tradition that leads to success. Think of how many moving parts there are on a successful team release! Integrating traceability skills and tools into daily work in a way that continues to value traditional Traceability (we still need reports for regulatory bodies, for example!) but also leaves room for new complex skills to emerge that mirror your specific favor of product delivery!
Read Forrester Report about the use of Modern Traceability and how it improves developers’ ideas, processes, and software.
Using stakeholder, system, hardware and software requirements to build a professional wireless microphone.
In the post below—the last of three transcribed from his Writing Good Requirements workshop, with notes and slides from his presentation deck included—Jama Consultant Adrian Rolufs explains common problems teams go through, and how to avoid them. (See Part II here.)
==Start Part III==
Let’s look at an example product using my audio background. I’m going to take a circuit that goes into a professional wireless microphone—the kind of high-performance microphone you’d see someone on a stage, like a MC or a musician, use.
It’s got to be able to handle a wide, dynamic range, meaning it has to be able to record very loud signals and very quiet signals, all with very high quality, and it’s got to be powered off of a battery so that it can he handheld, meaning the connection to the system will be wireless.
So we’re going to talk about some of the requirements that go into the chip; one of the main chips that goes into a solution like this.
First we’ll start at the market or stakeholder requirements level. Often, they’re called stakeholder requirements because stakeholders can be more than just customers.
In most product development organizations customers have requirements, but internal teams also have requirements.
So if I’m building a chip, for example, I have quality requirements that my quality department is going to dictate, but will also be influenced by the customer’s requirements.
And I probably have a production test organization that has to test every one of these devices as they go out the assembly line.
These devices are going to have requirements concerning what kind of access they need to internal circuits, and what kinds of circuits they need to enable them to test in a timely manner—things like that.
The development team might also have requirements; for example, they need to be able to reuse certain amounts of existing circuitry to stay on schedule, or requirements around data costs.
The point is that what we call stakeholder requirements is really a broad category. It could be anybody who has an influence on the product development.
Let’s look at some examples—these would most likely come from customers—which would be focused on the functionality and performance of the device. I’ve got three examples here: One is good and recommended; two are not.
We’ll start with the first one. Say we need a product that can input a microphone signal, convert a signal with two digital audio signals, have two different gain stages and consume less than 20mA while operating.
This is the sort of thing you’d likely hear directly from the customer but not necessarily the sort of thing I’d want to write down as requirements.
This brings up a couple of issues.
First, I’ve got a bunch of requirements mixed together, so it would be easy to miss something, and also it presupposes a certain solution.
It could be this is the right solution, but it assumes certain solutions, so it’s talking about internal details that are over‑constraining the design team.
The team can come up with a different gain structure that works and achieves the results, but doesn’t use 20dB and 0dB of gain. What’s wrong with that? Why do I need to over‑constrain them?
So those are some of the problems with the first one.
Second, customer X needs a 140dB microphone amplifier with a digital output for less than 50 cents. The microphone amplifier shall be low power.
This is the sort of thing marketing might write, because it’s focused on the customer’s request: They need it at a certain cost and everything should always be low power.
It’s very difficult to actually meet these kinds of requirements.
140dB—well, what is that? That’s just a ratio number; I don’t know what that actually is a measurement of. I need some more specificity around that.
As for 50 cents, you have no idea what the solution is yet so 50 cents may or may not be achievable, but it’s good to know.
And then the last one, low power; that can mean almost anything. Low power in one industry could be high power in another, so specificity around what low power means would be beneficial.
So in that case, the first example is more specific and has more detail—although both of the first two are not very atomic so it would be easy to miss things.
The last example talks about two things.
The first one has a problem statement. I love problem statements because they really tie back to the value the solution can offer. It’s giving me some context around what’s in the market today and what the problem is.
It’s saying in the market there are high dynamic range microphones which transmit digitally, and it requires circuitry that’s expensive and large or high power to obtain the necessary performance.
And from that I know that a solution is out there, but that solution is difficult, hard to use or hard to implement, and it can be expensive and it may or may not provide the necessary performance.
You can see how this helps outline the idea of what kinds of problems I need to solve and where the most value is in design.
So based on this, I would know that hitting the audio performance is important, and getting a small solution size that’s low power is also important; those are the key constraints.
To make that have a specific power consumption, say the solution shall consume less than 75mW while in operation.
Now, the other benefit here is 75mW; it’s an actual power number, whereas in the first example I had a current but without knowing the voltage I don’t what the power consumption is, so that’s also not a great example.
So in this case, the last one is the one I would recommend; it has more constraints and a good set of stakeholder requirements. With that, the design team has a good idea of what their goals are, but they’re not over‑constrained.
Now for the next level of detail: Once we have a set of stakeholder requirements, or at least a draft, we can start looking at system requirements. The system requirements are what we’re actually going to build a product against.
We’re not going to build a product directly against the stakeholder requirements because we could have multiple stakeholders and we need to consolidate their requirements into one set.
Or, certain stakeholders may ask for things that we actually end up not satisfying, but we still know that we can build a successful product.
So that translation from stakeholder requirements to system requirements provides the clarity and explicit decisions around what we’re going to do, what we’re not going to do, and what the actual requirements are for this project.
Now, one of my favorite examples of system requirements is the first one—absolutely nothing—and I see this time and time again.
I can’t count the number of times where I see people skipping the system requirements when they’re building a system.
If you’re an engineer responsible for low-level details, how do you know if those low-level details are the right details? Well, you need system requirements first, so we definitely don’t want to skip this level.
Now, the next one: The solution shall have two differential inputs using instrumentation amplifiers. The instrumentation amplifiers shall be followed by sigma‑delta ADCs. These are really low-level component requirements.
We’ve already jumped to the conclusion that we’re going to have a specific architecture in the hardware. What if part of the solution needs to be software? We haven’t said anything about that and we could already be over‑constraining the design team when some other architecture would be more appropriate.
It could be an instrumentation amplifier is not the best choice. We don’t need to constrain that at this level. So the last example here is really a better example of system requirements.
What about power consumption? It’s going to 20mA while in operation. I said before, current on its own is not necessarily the best example. With this you would typically provide a supply voltage range so then it would become clear.
What about the signal levels? Stating what the signal range needs to be provides a lot of detail around what the architecture of the design needs to be, without over‑constraining it.
And then, the overall end‑to‑end, signal‑to‑noise ratio: 140dB A‑weighted gives me a very clear statement of the overall performance, again without over‑constraining.
So for system requirements I like that last one.
These system requirements are all focused on the performance of the signal path. There should also be some system requirements here that talk about constraints on size, constraints on packaging and things like that.
Now we know we need to build something that consumes relatively low power, takes in a very wide dynamic range signal and maintains the quality of that. So we can start talking about architectures in response to these system requirements.
Let’s say we use a hardware device that has analog to digital conversion with two signal paths, both of which have medium performance but which we can combine together to obtain high performance, and that’s actually the common solution in the application.
And then we use a software algorithm to combine those signals, so we’re going to need a DSP to run the software algorithm and process the signal to output this resulting signal of 140dB A‑weighted signal noise ratio.
Based on that, we can now talk about the hardware‑specific requirements.
Here are some examples of different possibilities. The first one is a block diagram of the architecture.
I’m visual; I love block diagrams. I love schematics because they’re very intuitive. I can relate to them very well. They don’t make good requirements, unfortunately. It’s very difficult to test a diagram. It’s very difficult to make sure you didn’t miss anything in a diagram. So having a diagram on its own is not sufficient.
A really good solution is a diagram complemented by a set of requirements that attach to every important detail of that diagram.
That way, visual people have something to see, but we also have atomic requirements that we can test against and trace to make sure we didn’t miss anything, and also so we can manage changes.
If I make changes to this diagram based on changes to the architecture or customer requirements, it might be hard to actually know what those changes were, whereas if I have individual requirements I can track, I can easily know.
The second example is just a description of functionality, a response to the requirements. This is saying what the signal path of the device is; the architecture is describing a specific part number. This is down in the design descriptions where this belongs. It’s not hardware requirements.
So the last example is one I like for hardware requirements. We’re talking power consumption; we’re getting more specific.
We know that I’m building a chip, the power consumption is going to vary and I want to know what it’s typically at and what its maximum can be, so we’re specifying that.
Again, we’re repeating the input signal level because that input signal level was a requirement on the system that’s also a requirement on the hardware.
There is some duplication, but it’s there to explicitly say that this is a requirement on the hardware. I won’t see a requirement for 17uV RMS to 1V RMS on the software, because the software is never going to know about volts; it’s going to know about digital signals.
So even though there is duplication it’s done to make the decisions and the traceability explicit. So then I have requirements on the specific architecture.
Now that we’re down at the low-level and component requirements, the hardware requirements, we can start talking about specific solutions. We’ve got to get into the details of what the solution is actually going to be.
So in this case, in the hardware requirements, you’ll likely see requirements that dictate a certain solution, but that’s okay because it’s quite likely that the design team is the one writing these requirements, so they’re the right ones to make that decision.
As you probably have guessed by now, the last one is my recommendation for well‑written hardware requirements.
The last example is software requirements.
I see a lot of teams that just skip software requirements entirely and go straight to writing code. It’s really fun to write code, really satisfying, but if you don’t have any requirements, you’re starting without clear directions. We need some requirements.
The second example, some descriptions of functionality, is written as a shall statement. It sounds like a requirement but I’ve got a bunch of stuff mixed together.
I’m talking about two signals. I’m talking about what their performance is. I’m talking about the output. There is too much stuff mixed together here, so the third one is the recommendation: talking about specifics.
I am going to develop this software for a specific DSP, the Tenscilica HiFi 3. It’s going to perform a specific function. It’s going to take two audio signals and it’s going to combine those into one.
(Note: I’d probably need more detail around this. This is probably not enough by itself but I didn’t want to fill the screen with the requirements.)
And then, what’s the sample rate going to be? This algorithm is going to be designed for a specific sample rate or multiple sample rates. It’s an important characteristic of the algorithm. Let’s make sure that’s captured in requirements.
So that is exactly what I would recommend, and in each of these there are a lot more requirements that go along with this. These are just a couple of examples in each category.
Many teams mix up requirements and specifications. It’s very common.
You need to make sure you have a clear understanding of each of them and when to use them. It’s not always easy to decide which one is which, so it’s absolutely critical to have that discussion with your team.
What I see a lot of teams doing is skipping levels of hierarchy, jumping straight from high-level customer requirements down to detailed requirements or detailed specifications. Do that and you’ll have a very difficult time proving that you built the right thing.
It could be you’re operating fast and loose and you’re okay with that. Maybe that’s okay for a very small team in a very small organization. But in every other situation, it’s unlikely that you’d be building something so uncomplicated that you could get away with it. It’s high-risk.
So make sure that you have at least stakeholder requirements, client requirements and some kind of detailed specifications.
That’s the bare, bare minimum for any kind of product. More likely you need more.
What I recommend:Make sure you have a clearly defined process with clear levels of your requirements. If you don’t think you have that, discuss it with your team. What levels do you need? Which one of those diagrams [more in posts Part I and Part II] would be appropriate for your project?
And then there’s the scary question: Do you even use requirements?
Some teams plow ahead without requirements. Think about what kind of problems that can cause:
Maybe you’ve built products that have not been successful, that maybe needed a late change or maybe even failed, and you had to develop a new product in order to be successful.
Perhaps you’ve been in a situation where you later learned you missed some important details along the way and realized that you barely got away with it. That’s high-risk too.
When you start with an understanding of the roles different levels of requirements perform, you’re less likely to invite risk and add complications during development, and are much more likely to build the right product.